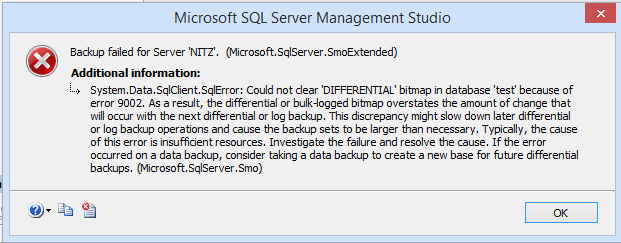
FlushCache: cleaned up 3194 bufs with 1259 writes in 148817 ms (avoided 485 new dirty bufs) for db 5:0 average throughput: 0.17 MB/sec, I/O saturation: 92, context switches 765 last target outstanding: 6880, avgWriteLatency 12
we might have noticed the above message in SQL Server 2012 error logs
When is this message written?
The above message is written in SQL 2012 when it find that long checkpoint happened, prior to SQL 2012 we need to enable Trace Flag 3404 to log checkpoint information in error log, So in SQL 2012 it write all checkpoint information's to error log if trace flag 3404 is enabled or if find a Long checkpoint happened
Long Checkpoint:A check point which have exceeded the configured recovery time time interval is called log check point.in my case i am using the default configuration '0' in instance level which is equal to 1 minute,so my checkpoint of database with db id 5 have crossed 1 minutes, to be precise the logged checkpoint took 148817ms (148.8 Sec) where the recovery interval is 60 Seconds
Whats next?if you recovery interval is 60seconds(default) and you are ok if it takes more time the configured then blindly ignore the and carry on with other works
but
What if i am worried about recovery time interval?
So now you have two mainly two options
1)Check your storage performance (in my case i observed I/O bottleneck and Storage administrator increased the IOPs and issue was fixed)
2)Reduce the number of dirty pages which in turn reduce the work of checkpoints
If you are ok with a bit delayed recovery and don't want to see checkpoint messages in your error log then you can increase the recovery time in instance level or SQL 2012 provide option to change in DB levle also, but i would say do a good study and testing before you change the target recovery time
we might have noticed the above message in SQL Server 2012 error logs
When is this message written?
The above message is written in SQL 2012 when it find that long checkpoint happened, prior to SQL 2012 we need to enable Trace Flag 3404 to log checkpoint information in error log, So in SQL 2012 it write all checkpoint information's to error log if trace flag 3404 is enabled or if find a Long checkpoint happened
Long Checkpoint:A check point which have exceeded the configured recovery time time interval is called log check point.in my case i am using the default configuration '0' in instance level which is equal to 1 minute,so my checkpoint of database with db id 5 have crossed 1 minutes, to be precise the logged checkpoint took 148817ms (148.8 Sec) where the recovery interval is 60 Seconds
Whats next?if you recovery interval is 60seconds(default) and you are ok if it takes more time the configured then blindly ignore the and carry on with other works
but
What if i am worried about recovery time interval?
So now you have two mainly two options
1)Check your storage performance (in my case i observed I/O bottleneck and Storage administrator increased the IOPs and issue was fixed)
2)Reduce the number of dirty pages which in turn reduce the work of checkpoints
If you are ok with a bit delayed recovery and don't want to see checkpoint messages in your error log then you can increase the recovery time in instance level or SQL 2012 provide option to change in DB levle also, but i would say do a good study and testing before you change the target recovery time